
Top 35 Machine Learning Interview Questions 2022
Are you lacking the confidence to appear for the Machine Learning (ML) interview? Well, don't be anymore. Prepare yourself with iCert Global's best picked frequently asked ML interview questions 2022.
Machine Learning (ML), Deep Learning (DL) and Artificial Intelligence (AI) are among the most popular and emerging technologies across the world. As the world's dependencies on these techs increase, so do its job opportunities or roles.
However, landing in these jobs does require a lot of effort and in-depth knowledge, as surpassing these interviews is never a piece of cake. If it was, then most around you would be ML, AI or DL practitioners.
Since we never let our audiences down nor demotivate them to pursue their dream jobs; therefore, today's blog is just for you. This comprehensive blog focuses on those striving to crack the machine learning job interviews.
Here we will see 35 sure-to-ask ML interview questions for 2022 that will revise all the required skills and necessary concepts. So, stay tuned.
You may also like: How ML Became a 2022 Tech Trend?
35 Sure-to-ask ML Interview Questions with Answers for 2022
Q1. What are different types of Machine Learning (ML)?
There are 3 types of ML:
1. Supervised Learning: Here ML models make predictions based on labelled or prior data. Labelled data means data sets that are given tags, making it more insightful.
2. Unsupervised Learning: Unlike the first type, here, there isn't any labelled data. An ML model can determine the input data's fallacies, patterns, and relationships.
3. Reinforcement Learning: Here, the model can learn based on the rewards it acquired for its past actions. For instance, consider an environment where an agent is operating. It is given a target to achieve, so every time it steps towards the target, it is given positive feedback. If the action taken is away from the objective, negative feedback is given.
Q2. What is variance and bias in Machine Learning?
- Variance: The number generates prediction difference over a training set and the expected value of other training sets. A high variance may result in significant output shifts; hence a model's output must be of low variance.
- Bias: It is the model's average prediction Vs the accurate value. If the bias value is high, then the model prediction isn't precise. Therefore, the value of the bias must be as low as possible to make the desired predictions.
Q3. What is Overfitting in Machine Learning?
Overfitting is a situation that happens when an ML model learns the training set too well, considering random shifts in the data as concepts. These affect the model's ability to generalize and not apply to new data.
For instance, when a model is provided with the training data, it shows 100% accuracy. However, when the test data is leveraged, there might be anomalies and low efficiency, and such condition is known to be Overfitting.
Q4. How to avoid overfitting in Machine Learning?
Some common ways to avoid overfitting in ML are:
- Regularization (artificial forcing ML model to be simpler).
- Cross validation (splitting datasets into two: testing and training datasets. Why? For tuning hyperparameters with only original training set).
- Ensembling (combines predictions from myriad separate models. 2 types of Ensembling - Bagging and Boosting)
- Make simple model with fewer parameters and variables.
- Remove irrelevant input features to enhance model generalizability
Q5. Name 5 popular Machine Learning algorithm?
- Support Vector Machines
- Decision Trees
- Nearest Neighbor
- Neural Networks or Back Propagation
- Probabilistic Networks
Q6. How will you handle a missing data in a dataset?
Two productive methods to handle a missing data are used in Python Pandas, and they are:
- IsNull() and dropna() - finds those missing data rows or columns and drop them.
- Fillna() - entire replacement of wrong values with a placeholder value.
Q7. How do you choose a Classifier based on training dataset size?
When a training set is small, the ML model with the correct bias and low variance works better as they are less likely to cause overfitting.
For instance, Naive Bayes (a classification algorithm) works best with an extensive learner. Models with high variance and low bias result in better performance due to their potential to operate fine with complex relationships.
Q8. What is cross validation in Machine Learning?
This technique allows a model to increase the performance of the given ML algorithm, which is provided with some sample data.
Cross-validation in ML splits the dataset into smaller parts consisting of the same number of rows. A random part is chosen as a test set, and the rest kept as train sets. Some of the approaches used in cross-validation are:
- K-fold
- Leave p-out
- Holdout method
- Stratified k-fold
Q9. What is difference between training set and test set?
Training Set:
- It is examples provided to the ML model to analyze and learn
- 70% of the total data is considered as the training dataset.
- To train the mode, labelled data are used.
Test Set:
- It is used to test the hypothesis accuracy produced by the ML model.
- Out of the total data, the remaining 30% is derived as testing dataset
- Here the model is tested without labelled data and then outputs are verified with labels.
Q10. Explain 3 stages of building a model in machine learning?
1. Model building - Select a suitable algorithm for the model and train it according to the requirement
2. Model testing - Test the model accuracy using the test data
3. Applying the model - Once tested, make necessary changes and leverage final model for real-time projects
Q11. What is the difference between KNN and K-means Clustering?
|
KNN |
K-means |
|
Supervised ML algorithm |
Unsupervised ML algorithm |
|
Labelled or identified data is provided to the model |
Unlabelled or unidentified data is provided to the model |
|
It is a Classification algorithm |
It is a Clustering algorithm |
|
Model matches the points based on the distance from the nearest points |
Algorithm creates batches of points depending on the average distance between distinct points |
Q12. What are the functions of Supervised Learning?
- String annotations
- Regression
- Classifications
- Time series prediction
- Speech recognition
Q13. What are the functions of Unsupervised Learning?
- Find data clusters
- Find new observations or database cleansing
- Determining interesting data directions
- Detect low-dimensional data representations
- Interesting coordinates and correlations
Q14. What is a confusion matrix?
A Confusion Matrix (error matrix) is a comparison summary of model predictions and actual value labels. It is represented using an NxN matrix, where N is the no. of classes.
Each row of the matrix indicates the predicted class instances, and each column shows the actual class instances.
For example, consider the following confusion matrix, where:
- True Positives (TP) = 12
- True Negatives (TN) = 9
- False Positives (FP) = 1
- False Negatives (FN) = 3
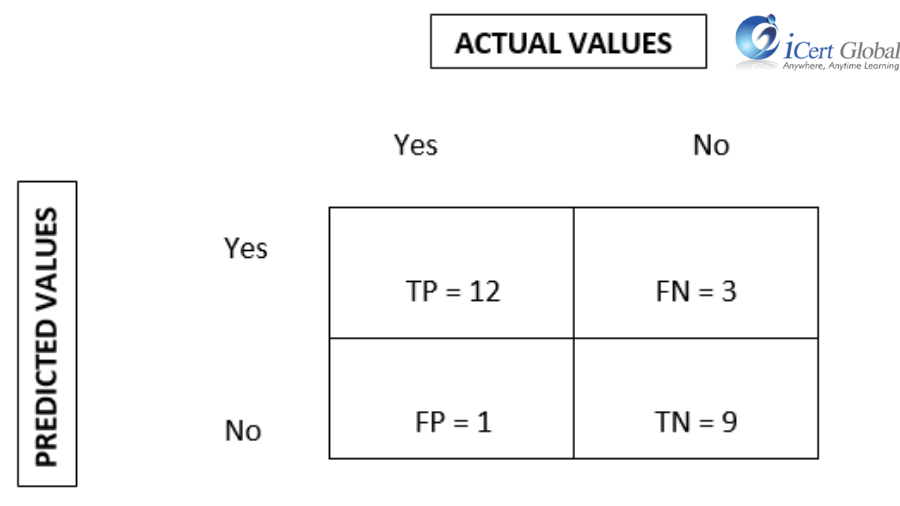
For actual values:
Total Yes = 12 + 1 = 13
Total No = 3 + 9 = 12
For predicted values:
Total Yes = 12 + 3 = 15
Total No = 1 + 9 = 10
Now, the accuracy of the model is calculated as
Accuracy = (TP + TN) / (TP + TN + FP + FN) = 21 / 25 = 84%
Q15. What is Deep Learning (DL)?
DL is a subset of machine learning. It involves systems that learn and think like humans using artificial neural networks. Since the model contains neural networks, the model can automatically determine which feature engineering to leverage and which not to use. DL also requires high-end system, due to huge computational power usage.
Q16. Compare Machine Learning with Deep Learning?
|
Machine Learning (ML) |
Deep Learning (DL) |
|
Based on the previous data, machines can take decisions on their own |
Artificial neural networks enable machines to take decisions |
|
Requires small amount of data for training |
Need massive volume of data for training |
|
No need of large machines. Can work on the low-end system |
Need high-end machines due to huge computational power |
|
Advance identification of most features and manual coding |
Machine learns from data features provided |
|
Issues divided into two parts and are individually solve and later combined |
The issue solved in an end-to-end manner |
Q17. Name few applications where Supervised Learning is used?
- Fraud detection
- Disease diagnosis
- Spam detection
- Sentiment analysis
Q18. In what areas is pattern recognition used?
- Information retrieval
- Computer vision
- Bio-informatics
- Statistics
- Data mining
- Speech recognition
Q19. What is Semi-supervised Machine Learning?
In this type of learning, the training data will contain a small amount of labeled data (supervised learning) and a huge amount of unlabeled data (unsupervised learning)
Q20. How is the suitability of a Machine Learning algorithm determined for a specific problem?
The following steps has to be followed in identifying the algorithm for a certain problem:
1. Problem classification
- Input classification: to determine whether data is from supervised learning, unsupervised learning, or reinforcement learning
- Output classification:
If:
-
- output is required as a class (classification technique used)
- output is a number (regression technique used)
- output is a different input cluster (clustering techniques used)
2. Check the available algorithms
3. Implement the algorithm
Q21. What are the techniques used in Unsupervised Learning?
There are 2 techniques:
1. Association: Here, association patterns are determined between different items or variables. For instance, an e-commerce site such as Amazon or Flipkart recommends other things for you to buy, based on previous purchases you have made, Wishlist items, other user purchase habits, etc.
2. Clustering: It involves data to be separated into subsets known as clusters. These clusters contain data that are similar to each other. Unlike regression or classification, different collections unveil different object details.
Q22. What are the different methods to solve Sequential Supervised Learning problems?
The different methods to solve the issues are:
- Graph transformer networks
- Hidden Markow models
- Sliding-window methods
- Conditional random fields
- Recurrent sliding windows
- Maximum entropy Markow models
Q23. How can one know which Machine Learning algorithm to choose for the classification problems?
Though there isn't any fixed rule to choose algorithm for the problem, but you can certainly follow these instructions:
- If the training dataset is large, use models with high variance and low bias
- If the training dataset is small, use models with low variance and high bias
- Test different algorithms and cross validate them, if precision or accuracy is a concern
Q24. How does recommendation engine work?
Once we buy something from e-commerce sites, these sites store the purchase data for future reference and determine products that are most likely to be purchased. This is possible because of the Association algorithm that determines patterns in a given dataset.
Q25. When is Classification chosen over Regression?
Regression technique is used when the target variable is continuous, while Classification is used when the target is categorical.
Example of Regression problems include:
- Estimation of product sales and price
- Prediction of rainfall amount
- Prediction of team score
Example of Classification problems include:
- Type of color
- Prediction of 'Yes or No'
- Estimation of gender
- Animal breed
Q26. What is random forest?
It is a Supervised Machine Learning algorithm that is used for classification problems. Random forest operates by creating multiple decision trees during the training stage. The algorithm has to choose from the majority decision as the final decision.
Q27. Define Precision and Recall?
Precision
Precision defines how many of the total positives are predicted as positives. For instance, the metrics used in document retrievals will be defined as the no of correct documents returned by the model.
Precision is determined as follows:
Precision = TP / TP + FP
Recall
Recall or Sensitivity is another vital metric that tells us the no. of True Positives (TPs) were predicted out of the total positive predictions. In simple words, it is said to be the ratio of TPs to all the positives in the actual values.
Recall = TP / TP + FN
Q28. How do we check a dataset or a feature's normality?
The normality of either can be checked using plots. However, there are a list of normality checking tests and they are:
- D'Agostino Skewness
- Anderson-Darling
- Kolmogorov-Smirnov
- Shapiro-Wilk W
- Martinez-Iglewicz
Q29. What is kernel SVM?
Kernel methods are algorithm classes for analysing patterns, and the most common one is the kernel Support Vector Machine (SVM).
Q30. What is meant by F1 Score?
It is a metrics that merges Recall and Precision into one metric for an average output value.
The formula to calculate F1 Score is:
F1 = 2 * (Precision * Recall) / (Precision + Recall)
Q31. What is meant by support vectors in SVM?
These vectors help in the creation of SVM models. The support vectors are data points which are closest to the hyperplane. It influences the orientation and position of the hyperplane. If the vectors are removed, it will alter the hyperplane position.
Q32. What is ensemble learning and why is it used?
It is a combination of results obtained from multiple machine learning models like classifiers to increase the accuracy for enhanced decision-making.
Ensemble learning is used to enhance prediction, function approximation, classification, etc., of a model.
Q33. How is Random Forest different from Gradient Boosting Machine (GBM)?
The major difference between Random Forest and GBM is the leveraging of methods, i.e., Random Forest used bagging method to advance predictions, while GBM uses boosting technique to do the same.
- Bagging: Here an arbitrary sampling is applied and datasets are divided into N. After that, using a single training algorithm a machine learning model is created. Using polling approach, the final predictions are obtained and is later combined. The advantage of Bagging approach is that it increases the model efficiency by minimizing the variance to eradicate overfitting.
- Boosting: Here, the algorithm strives to review and rectify the inadmissible predictions during the initial iteration. After that, the algorithm iteration sequence for rectification continues until a desired prediction is obtained. The advantage of Boosting technique is that it minimizes bias and variance to strengthen the weak learners.
Q34. What are the assumptions one must consider before beginning with Linear Regression?
There are basically 5 assumptions when starting with Linear Regression model and they are:
- No auto-correlation
- Linear relationship
- Multivariate normality
- No or less multicollinearity
- Homoscedasticity
Q35. Define AUC-ROC of Classification Metrics?
Area Under Curve (AUC) - Receiver Operator Characteristics (ROC) defines the degree of class separability by the model. The higher the score, the more the ability of the ML model to predict 1s as 1s and 0s as 0s. The curve is plotted using FP rate (FPR) on X-axis and TP rate (TPR) on the Y-axis.
The formula of TPR and FPR are as follows:
TPR = TP / TP + FN
FPR = FP / TN + FP
If AUC-ROC = 1, then models are predicting accurately and complete separability. If it is 0.5, then there is no separability, and the model is expecting unexpected results. If it's 0, the model is predicting the inverted classes.
Achieve Your Dream and Be a Part of ML Talent Pool
With technologies increasing day by day, the ocean of AI and data science opportunities is never-ending. Individuals who upskill their careers and be top-notch in these innovative techs can find many open doors with eye-catching salaries.
Looking forward to becoming a Machine Learning practitioner but not knowing where to stop by? Well, you are in the right place.
Enrol in iCert Global's Machine Learning (ML) course and be a certified professional now.
iCert Global is a one-stop solution that offers certification training courses in a wide variety of techniques, thus giving you a head start in this competitive world. Visit our website to find out the different technology courses.
Based on the level of experience, you may be asked to display your Machine Learning skills. However, this mainly depends on the role you are trying to achieve.
The Machine Learning interview questions with answers are the best-pick from our end, which will help you clear the interview on the first try.
Apart from the interview question preparation, it is also significant to have an adequate knowledge of Data Science.
About Us
Our company conducts both Instructor-led Live Online Training sessions and Instructor-led Classroom training workshops for learners across the globe.
We also provide Corporate Training for enterprise workforce development
Emerging technology certifications:
Artificial Intelligence (AI) & Deep Learning (DL) Rating 4.9/5 Stars, 12078 students enrolled
Robotic Process Automation (RPA) Rating 4.9/5 Stars, 10078 students enrolled
Machine Learning (ML) Rating 4.9/5 Stars, 958 students enrolled
Blockchain Rating 4.9/5 Stars, 1127 students enrolled
Comments (0)
Write a Comment
Your email address will not be published. Required fields are marked (*)
















.webp)







